Confusion Matrix
ตัวอย่างผลการทำนายจาก Classification Model
เราจะเริ่ม model ที่ใช้ทำนายแค่ 2 class ว่าผลที่ได้คือ positive หรือ negative
ถ้าเรากำหนดค่า positive threshold ไว้ที่ 0.5
0.7 , 0.3, 0.6 , 0.7 , 0.8, 0.1 , 0.4
แปลงผลเป็น class ได้เป็น
positive, negative, positive, positive, positive, negative, negative
เราลองเอาผลการทำนาย กับ ค่าจริง จาก dataset (Ground truth) นำมาเปรียบเทียบกัน
- Ground truth: positive, negative, negative, positive, positive, positive, negative
- Predicted: positive, negative, positive ,positive, positive, negative, negative
การวัดผลการทำนายโดย Model จะอยู่ในรูปแบบของ confusion matrix ซึ่งจะมีหน้าตาประมาณนี้
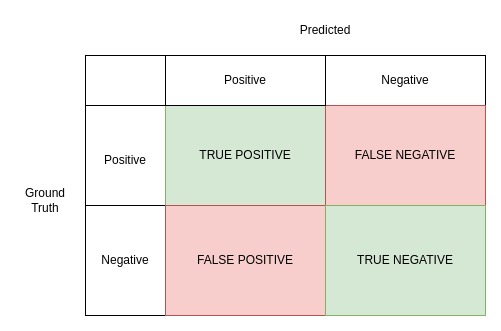
ผลจะถูกแบ่งออกเป็น 4 กลุ่ม
- TRUE POSITIVE จำนวนผลที่ ground truth เป็น positive และ predicted เป็น positive (ผลถูกต้อง)
- FALSE NEGATIVE จำนวนผลที่ ground truth เป็น positive แต่ predicted เป็น negative (ผล negative ที่ไม่ตรงความจริง)
- FALSE POSITIVE จำนวนผลที่ ground truth เป็น negative แต่ predicted เป็น positive (ผล positive ที่ไม่ตรงความจริง)
- TRUE NEGATIVE จำนวนผลที่ ground truth เป็น negative และ predicted เป็น negative (ผลถูกต้อง)
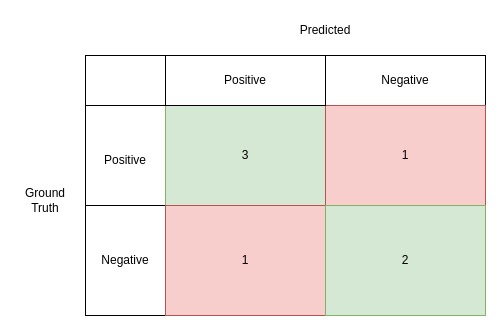
จากตัวอย่างผลการ predicted เราจะจับมาใส่ใน matrix จะได้ออกมาแบบนี้
ลองใช้ scikit learn เพื่อคำนวนหา confusion matrix
import sklearn.metrics
import numpy
ground_truth = ["positive", "negative", "negative", "positive", "positive", "positive", "negative" ]
predicted = ["positive", "negative", "positive" ,"positive", "positive", "negative", "negative"]
cm = sklearn.metrics.confusion_matrix(ground_truth, predicted)
confusion_matrix = numpy.flip(cm)
print(confusion_matrix)
array([[3, 1],
[1, 2]], dtype=int64)
เราจะนำ confusion matrix มาใช้เปรียบเทียบกันยังไงละ ว่าโมเดลไหน ดีกว่า
Accuracy
ในแง่ของการประเมินผลที่ได้จาก Evaluate จาก Model นั่นสำคัญสำหรับขั้นตอนงานวิจัย
เราสามารถคำนวนหา Accuracy ได้โดยสูตรนี้
$$Accuracy = \frac{True_{positive} + True_{negative}}{True_{positive} + True_{negative} + False_{positive} + False_{negative}}$$
Accuracy จะคำนวนสัดส่วนระหว่างการ predicted ที่ถูกต้อง กับ ผลการ predicted ทั้งหมด
เรามาลองคำนวนค่า Accuracy จากข้อมูลตัวอย่างกัน
ground_truth = ["positive", "negative", "negative", "positive", "positive", "positive", "negative" ]
predicted = ["positive", "negative", "positive" ,"positive", "positive", "negative", "negative"]
r = sklearn.metrics.confusion_matrix(ground_truth, predicted)
r = numpy.flip(r) # flip
acc = (r[0][0] + r[-1][-1]) / numpy.sum(r)
acc2 = sklearn.metrics.accuracy_score(ground_truth, predicted)
print(f'Accuracy from scratch: {acc}')
print(f'Accuracy from sklearn accuracy score: {acc2}')
ผลที่ได้คือ
Accuracy from scratch: 0.7142857142857143
Accuracy from sklearn accuracy score: 0.7142857142857143
Precision
precision จะเป็นสัดส่วนระหว่าง true positive กับ ค่า predicted ที่เป็น Positive ทั้งหมด
$$ Precision = \frac{True_{positive}}{ True_{positive} + False_{positive}}$$
ลักษณะสำคัญของ precision คือ ถ้า false positive หรือการทำ predicted ค่า positive ที่ไม่ตรงกับความจริง มีค่าน้อยลงเท่าไหร่ precision ก็จะมีค่าที่สูงขึ้นเท่านั้น
ground_truth = ["positive", "negative", "negative", "positive", "positive", "positive", "negative" ]
predicted = ["positive", "negative", "positive" ,"positive", "positive", "negative", "negative"]
precision = sklearn.metrics.precision_score(ground_truth, predicted, pos_label="positive")
print(f'sample precision: {precision}')
sample precision: 0.75
Recall
คำนวนจากสัดส่วนของการ predicted ผลที่เป็น positive กับ sample ที่เป็น positive ทั้งหมด เขียนเป็น สูตรได้ตามนี้
$$ Precision = \frac{True_{positive}}{ True_{positive} + False_{negative}}$$
ค่า false negative เป็นการ predicted ที่ได้ผลลัพธ์เป็น negative แต่จริงๆ ควรจะเป็น positive ยิ่งค่าน้อยเท่าไหร่ จะทำให้ recall มีค่าสูงขึ้น หมายถึงความถูกต้องใน predicted ค่า positive มีสูงนั่นเอง
ground_truth = ["positive", "negative", "negative", "positive", "positive", "positive", "negative" ]
predicted = ["positive", "negative", "positive" ,"positive", "positive", "negative", "negative"]
recall = sklearn.metrics.recall_score(ground_truth, predicted, pos_label="positive")
print(f'Sample recall: {recall}')
ค่าที่ได้คือ
Sample recall: 0.75
สรุปเกี่ยวกับการใช้งาน Precision และ Recall
- Precision ใช้สำหรับวัดความเที่ยงตรงของการ จำแนก sample ที่เป็น positive ส่วน Recall จะใช้วัดผลจำนวนการ predicted ที่ถูกต้อง สำหรับ sample ที่เป็น positive
- Precision จะสนใจเฉพาะ sample ที่ predicted เป็น positive เท่านั้น ไม่ได้สนใจ sample ที่เป็น positive ทั้งหมด ส่วน Recall จะสนใจเฉพาะ sample ที่เป็น positive ทั้งหมดและ predicted ได้ถูกต้อง โดยไม่สนใจ false positive
เลือกใช้อะไรดี Precision หรือ Recall
Precision เหมาะกับงานต้องการความถูกต้องสูง เช่น การจำแนกทางภาพถ่ายทางการแพทย์ ว่าเป็นโรคหรือไม่ ซึ่งต้องเที่ยงตรงแม่นยำ ส่วน Recall เหมาะกับการจำแนกว่า object ไหนเป็นสิ่งที่เราต้องการหา จาก sample ทั้งหมด ( อาจจะมีบาง object ที่เป็น false positive แต่ตรงนี้ไม่มีผลกับ Object ที่เราต้องการจริงๆ )